

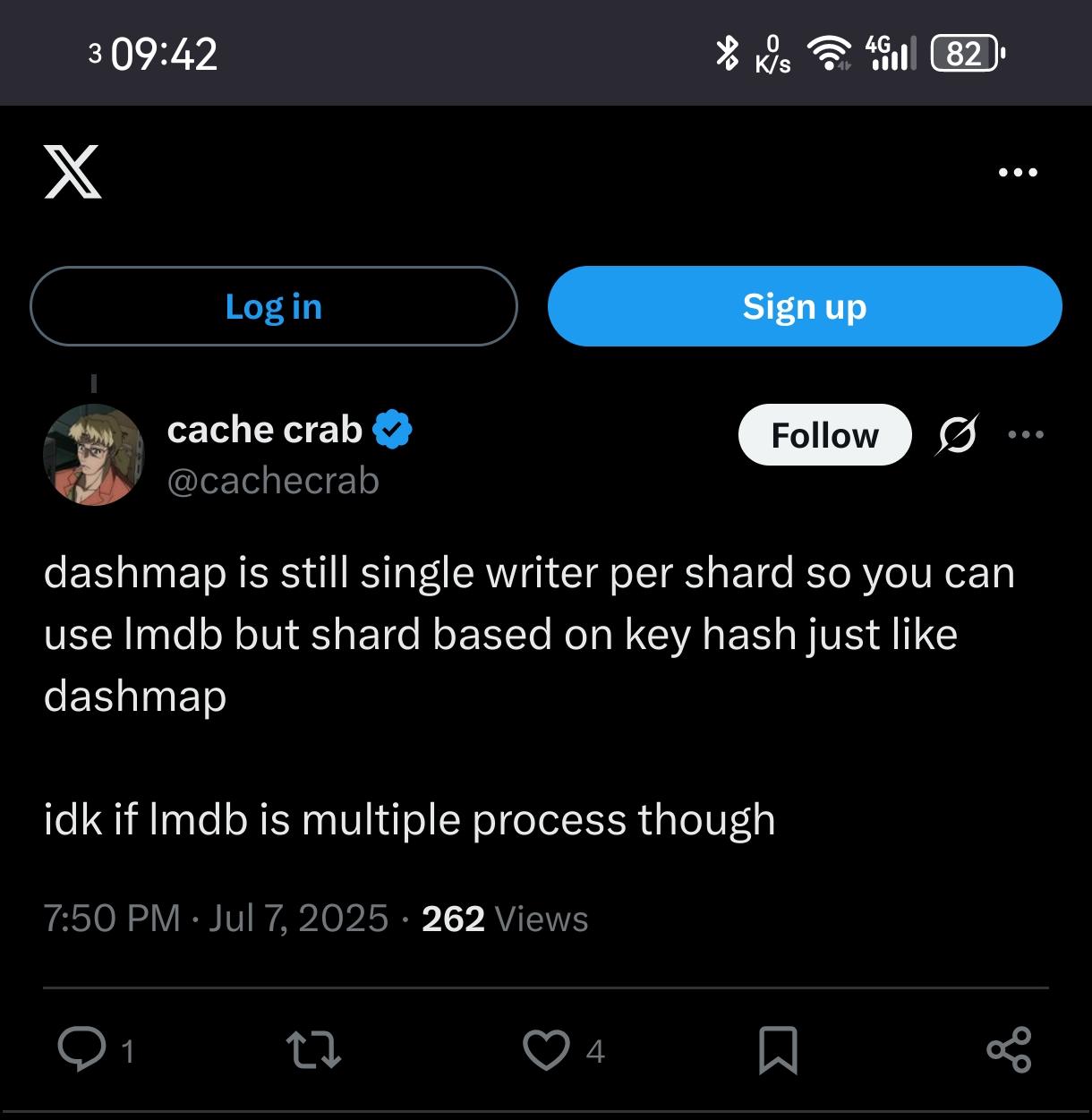
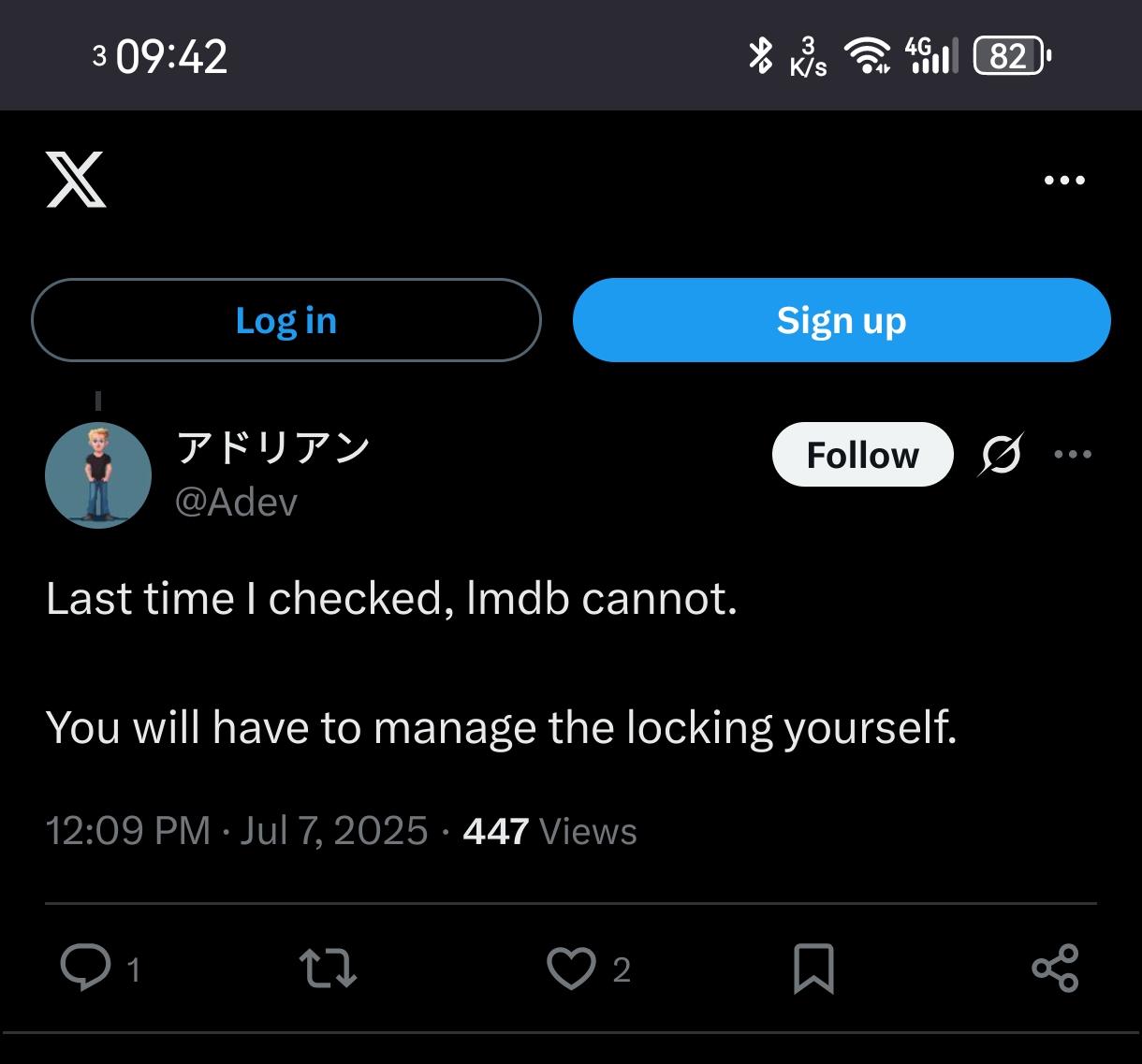
Investigate #LMDB as HLR storage
https://projects.osmocom.org/issues/3649
This Open Source Mobile Comm project appears to be an open source impl of a 3G network's backend software. But they're not using the standard 3GPP protocols, they're using their own home-grown stuff instead.
Looks like a toy, using SQLite3 as its HLR storage. Real 3G/4G networks use LDAP, lots of OpenLDAP in particular because nothing else scales enough, efficiently enough.
projects.osmocom.orgFeature #3649: Investigate LMDB as HLR data storage - OsmoHLR - Open Source Mobile CommunicationsRedmine






 3D data processing: mesh processing, point cloud operations, 3D visualization
3D data processing: mesh processing, point cloud operations, 3D visualization Report generation: automatic generation of HTML test reports
Report generation: automatic generation of HTML test reports Deployment tools: deployment solutions such as ONNX, TensorRT, shared memory, etc.
Deployment tools: deployment solutions such as ONNX, TensorRT, shared memory, etc.


